

Organisations have found that it is not always desirable to send data to the cloud due to concerns about latency, connectivity, energy, privacy and security. So why not create learning processes at the Edge?
What challenges does IoT bring?
Sensors are now generating such an increasing volume of data that it is not practical that all of it be sent to the cloud for processing. From a data privacy perspective, some sensor data is sensitive and sending data and images to the cloud will be subject to privacy and security constraints.
Regardless of the speed of communications, there will always be a demand for more data from more sensors – along with more security checks and higher levels of encryption – causing the potential for communication bottlenecks.
As the network hardware itself consumes power, sending a constant stream of data to the cloud can be taxing for sensor devices. The lag caused by the roundtrip to the cloud can be prohibitive in applications that require real-time response inputs.
Machine learning (ML) at the Edge should be prioritised to leverage that constant flow of data and address the requirement for real-time responses based on that data. This should be aided by both new types of ML algorithms and by visual processing units (VPUs) being added to the network.
By leveraging ML on Edge networks in production facilities, for example, companies can look out for potential warning signs and do scheduled maintenance to avoid any nasty surprises. Remember many sensors are linked intrinsically to public safety concerns such as water processing, supply of gas or oil, and public transportation such as metros or trains.
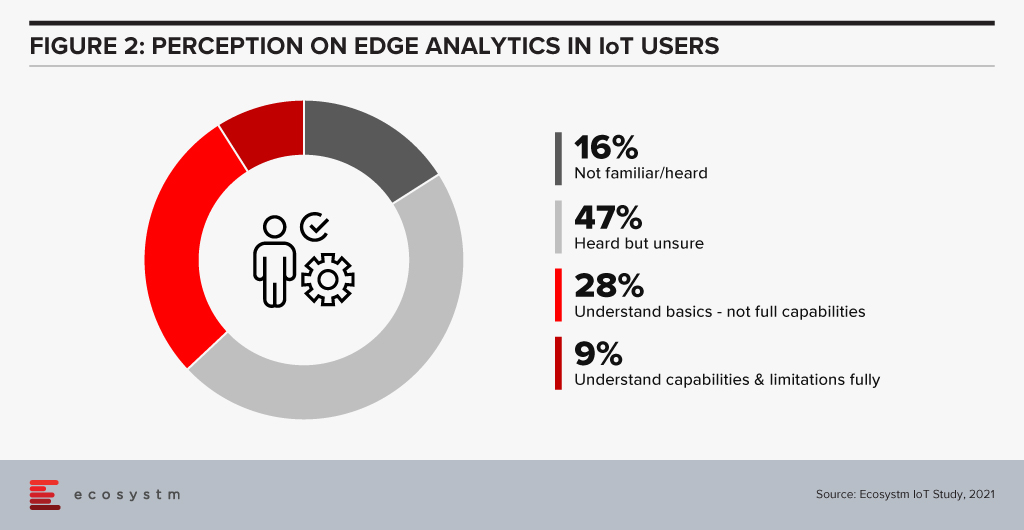
Ecosystm research shows that deploying IoT has its set of challenges (Figure 1) – many of these challenges can be mitigated by processing data at the Edge.

Predictive analytics is a fundamental value proposition for IoT, where responding faster to issues or taking action before issues occur, is key to a high return on investment. So, using edge computing for machine learning located within or close to the point of data gathering can in some cases be a more practical or socially beneficial approach.
In IoT the role of an edge computer is to pre-process data and act before the data is passed on to the main server. This allows a faster, low latency response and minimal traffic between the cloud server processing and the Edge. However, a better understanding of the benefits of edge computing is required if it has to be beneficial for a number of outcomes.

If we can get machine learning happening in the field, at the Edge, then we reduce the time lag and also create an extra trusted layer in unmanned production or automated utilities situations. This can create more trusted environments in terms of possible threats to public services.
What kind of examples of machine learning in the field can we see?
Healthcare
Health systems can improve hospital patient flow through machine learning (ML) at the Edge. ML offers predictive models to assist decision-makers with complex hospital patient flow information based on near real-time data.
For example, an academic medical centre created an ML pipeline that leveraged all its data – patient administration, EHR and clinical and claims data – to create learnings that could predict length of stay, emergency department (ED) arrival models, ED admissions, aggregate discharges, and total bed census. These predictive models proved effective as the medical centre reduced patient wait times and staff overtime and was able to demonstrate improved patient outcomes. And for a medical centre that use sensors to monitor patients and gather requests for medicine or assistance, Edge processing means keeping private healthcare data in-house rather than sending it off to cloud servers.
Retail
A retail store could use numerous cameras for self-checkout and inventory management and to monitor foot traffic. Such specific interaction details could slow down a network and can be replaced by an on-site Edge server with lower latency and a lower total cost. This is useful for standalone grocery pop-up sites such as in Sweden and Germany.
In Retail, k-nearest neighbours is often used in ML for abnormal activity analysis – this learning algorithm can also be used for visual pattern recognition used as part of retailers’ loss prevention tactics.
Summary
Working with the data locally on the Edge, creates reduced latency, reduced cloud usage and costs, independence from a network connection, more secure data, and increased data privacy.
Cloud and Edge computing that uses machine learning can together provide the best of both worlds: decentralised local storage, processing and reaction, and then uploading to the cloud, enabling additional insights, data backups (redundancy), and remote access.
